
This is the first in a series of posts on Data management with Nuvla. Nuvla is an edge management platform as a service, designed to make it easy for you to manage, monitor, deploy and update your containerised apps and edge devices.
Data scientists have to make sense of messy, unstructured data to uncover solutions for scientific, technological and business challenges. These blog posts are aimed at data scientists looking for a more efficient way to manage, process and analyse that data.
In these posts you will learn about:
- the set of features available in Nuvla
- what you can achieve with them
- how this works in practice.
Keep with us until the end, as we will give you an insight into the ESA GNSS Big Data project, which uses Nuvla for data management.
Making sense of large data sets
Large data sets, produced and stored on the edge and in the cloud, need to be made available for post-processing and analysis to facilitate extraction of valuable information. Nuvla enables this process by providing users with data management capabilities in the form of:
- data registration,
- a powerful search engine,
- meta-data updates,
- selection of applications that can work with particular data types and
- directing data processing applications to where the data is actually located.
All this is possible via a rich web UI and API.
Below, we describe a number of building blocks (or elements) and operations on them available in Nuvla to support user data management in distributed environments. We present you with a powerful “Open with…” pattern, allowing users to automatically deploy their data processing applications directly where the data is located.
Elements & operations of Nuvla data management
Nuvla defines a number of elements (resources) and operations on them that help users to work with their data stored on the edge or in the cloud. Let’s go through them:
ELEMENTS (RESOURCES)
Infrastructure-Service and Infrastructure-Credential
These resources contain endpoints and credentials of the storage (e.g. S3) and/or cluster (Kubernetes, Docker Swarm) where the data is located. The data resources (detailed below) reference these infrastructure resources.
Infrastructure-Service-Group
This allows grouping of cluster and storage Infrastructure-Services to identify storage and processing proximity.
Data-Record
This resource keeps information about the user data in a user-defined schema. The fields in the schema can contain scalars (e.g. strings, booleans) and collections (e.g. set of key/value pairs, geo-spatial points). It also allows users to link each particular data record with its location - Infrastructure-Service. The user can define and set a data type for each record. This helps to find applications supporting this data type.
Data-Object
This is an S3 object with a predefined workflow on it. It is a very powerful resource for working with data on S3 and is described in the online Nuvla documentation.
Data-Set
This provides a virtual snapshot view over the data defined by the user query on the data records or objects.
OPERATIONS
CRUD and actions
Nuvla provides a full set of CRUD operations over all the data elements, and extends them with a set of resource specific actions (see Data-Object documentation).
Query
A simple and powerful query language which allows you to query data records and data objects. A full text search is available for the data sets.
Each data record or object has a creation timestamp which means that they, as well as the data sets, can also be filtered by time. Nuvla allows users to have geo-spatial data fields in the data records and run point and shape queries over them.
Users can persist their queries over the data as data sets. This creates virtual dynamic snapshots over the data that can be acted upon - e.g. with “Open with…”.
Open with…
In Nuvla, applications can be marked with a list of data types they support.
By utilising the data binding defined on the applications and the data types in Data-Records, and in combination with knowing where the data is located (via the link of data to the Infrastructure-Service), Nuvla allows users to automatically direct the deployment of applications close to the data.
This operation is usually done on data sets. Launching an application on the selected data sets we call “Open with…” feature. At the moment, the data sets must reside on a single location, but we are exploring possibilities of deploying the user workloads simultaneously in multiple locations as well.
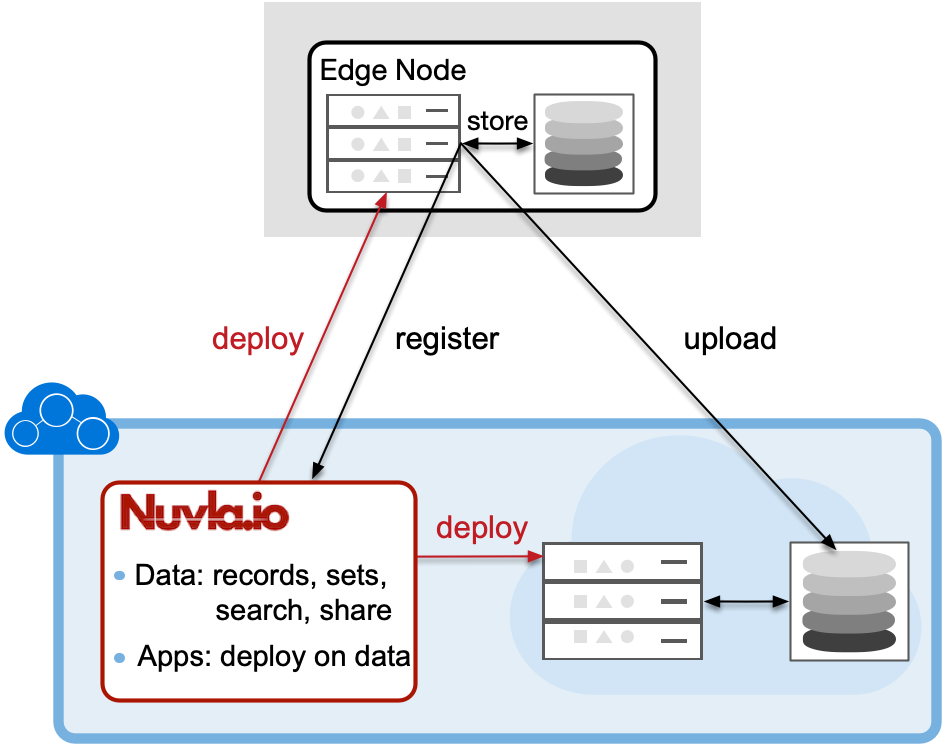
An example of data management workflow.
The rich set of functionalities described above allows our clients to push their boundaries by bridging the gap between edge and cloud. A good example of this is the GNNS Big Data Project.
A typical workflow of working with data could look as follows:
- Store files on the storage local to the place where the data was collected or produced,
- Register meta-data about the data and its location in Nuvla.
- Build and register queries over the data. This produces data sets.
- Tag the data by types that define which applications can work with it.
- Create applications that can work with the specific data types.
- Use “Open with…” feature to select data set(s) and launch the application on them.
Let’s go through the steps in more detail.
Steps 1. and 2. are usually combined into a store-and-register step:
Store data as files on local storage of the edge device and register the data in Nuvla. The local storage can be of any type. For example, it can be S3 Ceph RadosGW physically persisting data on Ceph pools defined on Ceph object store. Or it can be a distributed file system (e.g. NFS, GlusterFS, CephFS). In each of the cases, the stored files can be registered in Nuvla with information defining the reference to the edge device, type of the storage and path to the file on that storage. In the case of S3, this will be a reference to the S3 infrastructure service pre-defined by user in Nuvla, that has the endpoint of the S3 and, in turn, reference to credentials to access this S3 endpoint.
Step 3 allows users to create filters over the meta-data for which they registered their data. It can be geo-special queries or queries over the specific data sub-types, data creation time, etc.
Step 4 is possible as part of Step 2. or as a separate update action.
Step 5 is where users build applications from scratch or find existing ones in Nuvla App store, and add a corresponding data type binding to them. This signals to Nuvla that this app can work with the particular data type.
Step 6 Nuvla facilitates users with the deployment of the right application on the data at the location where the data is actually residing.
Building the described workflow can be achieved by combining the usage of Nuvla API, client API libraries (available in Python, C and ClojureScript), and web UI.
Nuvla as a meta-data catalogue
From the description of available resources, operations and the example workflow, we hope to have shown you that Nuvla acts as meta-data catalogue with links between data, infrastructure resources and applications. This allows for a rich set of functionalities and patterns to be built around that by any user.
What’s next?
In the next posts we will explore how to use the data management features of Nuvla using the UI and API. This will help you understand how this actually works in practice and allow you to apply this knowledge to managing and processing your own data across edge and cloud.


