
This is the second blog post in the series on Data management with Nuvla. Nuvla is an edge management platform as a service, designed to make it easy for you to manage, monitor, deploy and update your containerised apps and edge devices.
Here we will show you how easily you or your customers can manage any data on S3 (store, register, search and download) either on Cloud or Edge using Nuvla.
Easy handling of S3 objects with Nuvla
In the first blog we covered at a high level the ways it is possible to register and use data on the Edge or Cloud with Nuvla. Here we will delve into the details and present a cool feature of Nuvla that greatly simplifies the building of your Edge and Cloud data catalogues and providing access to the data to any user.
But before we do that, here are the benefits of doing this with Nuvla:
- No S3 client is needed! Yes, that’s right.
- No S3 credentials are shared with your users/customers for data upload and download.
- Categorisation of your data with an arbitrary schema.
- Reach and fast search over your data’s meta-data.
- Nuvla application orchestrator leveraging the meta-data catalogue and starting applications where the data is and with the data attached.
This translates into the following:
- greatly simplifies your data management
- provides a complete integration of your data across clouds and edge
- removes hurdles and erases boundaries for data engineers and developers.
This is a holistic approach to management and processing of your data wherever it is. In other words, it creates a continuum between the cloud and the edge.
Register S3 Endpoint
As we will be working here with S3, we need to tell Nuvla the S3 endpoint and credentials. You can use any S3 endpoint as long as it has AWS S3 compliant API: e.g. MinIO, Ceph RadosGW, etc., and it doesn’t matter whether it’s running at the Edge or in the Cloud.
To add the S3 endpoint and credentials, use the Infrastructures and Credentials tabs in Nuvla.
For more details see our documentation on management of Infrastructure Services in Nuvla.
Here it’s how you can do this with our Python API library.
from nuvla.api import Api as Nuvla
from nuvla.api.resources.infra_service import (InfraServiceGroup,
InfraServiceS3,
CredentialS3)
nuvla = Nuvla()
nuvla.login('<login params>')
group_id = InfraServiceGroup(nuvla).add('S3')
infra_s3 = InfraServiceS3(nuvla).add('https://s3.endpoint', group_id , 'My S3')
s3cred_id = CredentialS3('s3 key', 's3 secret', infra_s3, 'My S3 cred')
Upload data to S3 and Register it in Nuvla
Once your S3 endpoint is registered in Nuvla, you are ready to start uploading data to S3 and registering it with Nuvla.
Here are the steps describing how this is done (any HTTP client can be used):
- Create data-object record by providing S3 bucket, object path, and the ID of S3 credentials. This will return the ID of the new data-object resource.
- Call the upload operation on it. This returns the S3 pre-signed upload URL.
- Upload your object to S3 using the pre-signed upload URL from 2.
- Set the object as ready by calling the ready operation.
As you can see, this can easily be scripted or programmed in any language that has an HTTP library. The bucket will be created on S3 by Nuvla if it doesn’t exist when calling the upload operation (see step 2. above). Also, steps 1., 2. and 4. can be done using the Nuvla UI. Additionally, by setting the appropriate ACLs (Access Control List) you control who can see the object and what operation can be performed. Usually you set read-only ACLs for the user by forbidding the deletion of the object.
In our Python API library we wrapped the above four actions into a single call for your convenience.
from nuvla.api.resources.data import DataObjectS3
obj_id = DataObjectS3(nuvla).create(open('data/african-lion.jpg').read(), 'cloud.animals', 'africa/african-lion.jpg', s3_cred_id)
There are more options to the object creation available - like setting object content type, md5sum, tags, giving the object a friendly name in Nuvla, etc.
More information can be found in our online documentation:
Data management model and Example on data management.
Search
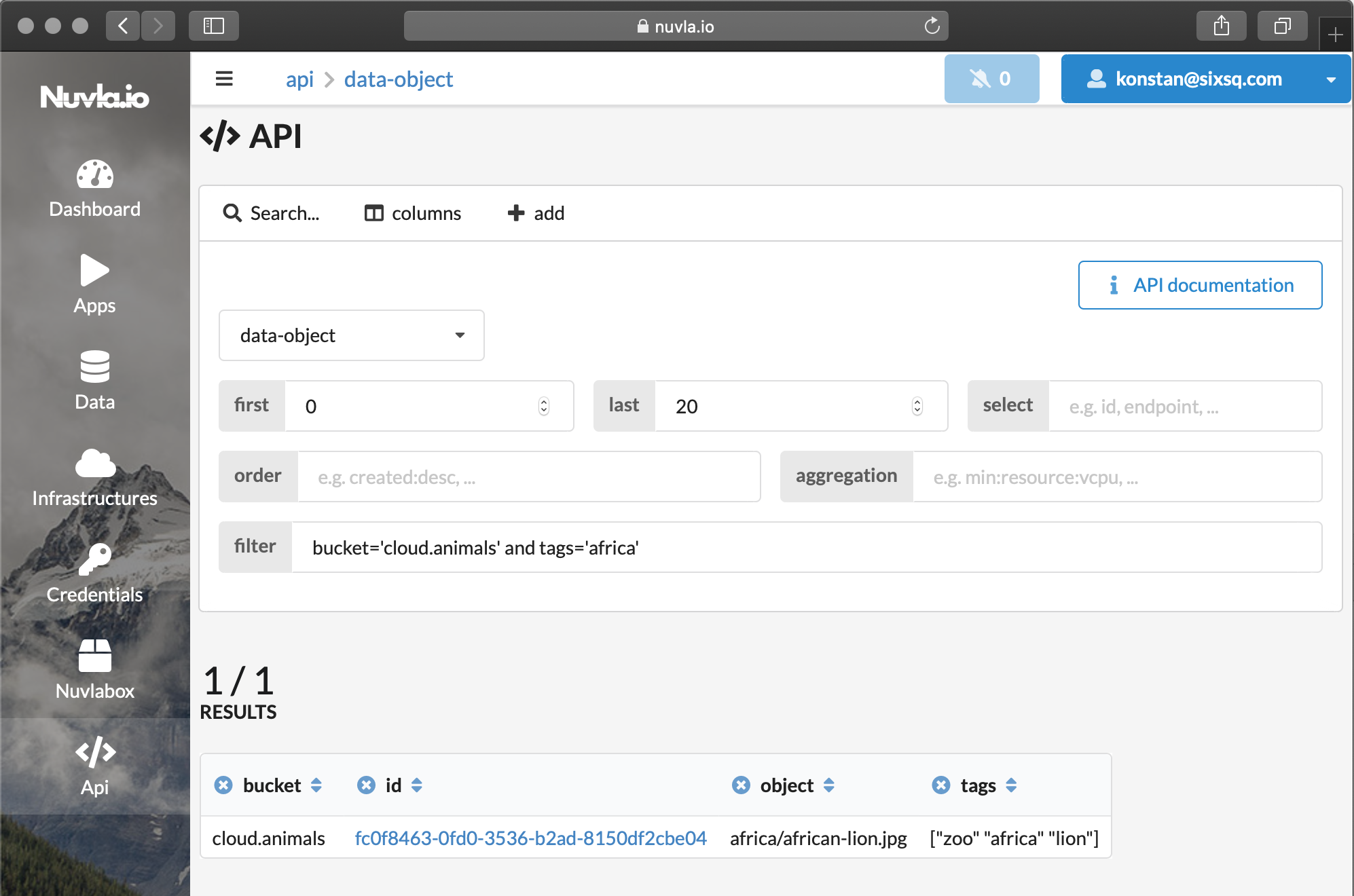
Nuvla has a powerful search API. Now, that your object is in S3 and registered in Nuvla, it can be found by searching data-object resources either directly through the API or the API section of the UI, as seen in the screenshot below.
Because there is no need to search through objects’ meta-data directly on S3, the operation is extremely fast, leveraging Elasticsearch that is used by Nuvla under the hood.
Download: No S3 credentials or S3 client needed
When the required object is found (see screenshot above; bucket and tags keys are used), the user can either:
- request S3 pre-signed object download URL from Nuvla by clicking on the download button (see screenshot below), or
- start an application requesting this object to be mounted to or already present in the container.
This second - more powerful option - will be described in our next blog posts.
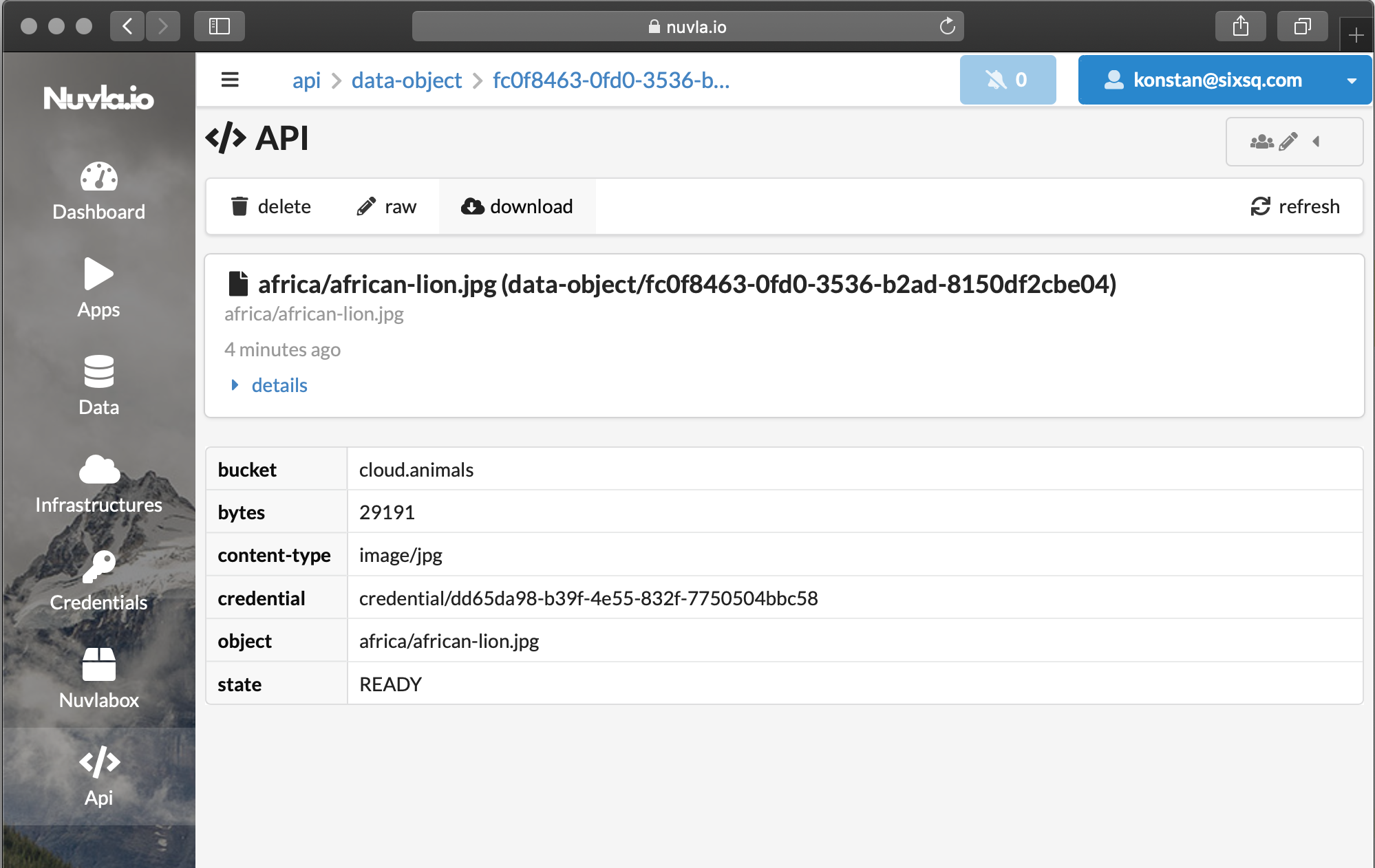
As you can see, users with whom you’ve shared the access to the data-object in Nuvla, don’t have to possess credentials of your S3. And now downloading the file from S3 can be done with any HTTP client, as in the example below:
$ curl --output lion.jpg "https://sos-ch-gva-2.exo.io/cloud.animals/africa/african-lion.jpg?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20200531T220403Z&X-Amz-SignedHeaders=host&X-Amz-Expires=899&X-Amz-Credential=EXOcc19d8afde0f4eac4675426a%2F20200531%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Signature=f3817e96207fc2dae41da804fade1c490f44c49aa85a821656b7bc7166994517"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 29191 100 29191 0 0 140k 0 --:--:-- --:--:-- --:--:-- 139k
$ ls lion.jpg
lion.jpg
Next steps
In this blog, we’ve covered a very cool feature of Nuvla that allows you to:
- store, search, and download your data to/on/from S3;
- share data with your users/clients without giving them credentials of your S3;
- and you don’t need an S3 client neither for object upload nor download.
In the next blog post on this topic, we will cover in details data-records.
While, as you could already see, tags on data-object gives a sense of meta-data that can be used for object identification, data-record is specifically designed to be your object’s meta-data store. After that we will demonstrate how to start your container application on a set of data using Nuvla’s data-set. We will finish by describing how all this works in the GNSS Big Data project, where Nuvla is at the heart of the distributed platform for GNSS data collection and processing at the Edge and in the Cloud.
Follow us on LinkedIn or Twitter to make sure don’t miss when the next blog is published!


